Introduction
In the last decades, the use for AI skyrocketed as well as their need for curated and ready-to-use data. A well-known fact about AI is that the quality of the results depends on the quality of the data ingested. Most of the models require this data to be curated and prepared beforehand to enhance the overall performances of AI outputs. Besides, data analysis and preparation pipeline engineering are known for being high-effort tasks because of their iterative nature. They require knowledge from AI and data experts as well as from domain-specific experts to properly seize the attention points which shall be considered.
As AI4SWEng aims to facilitate Software Development and Testing, it also encompasses AI-based software and the requirements related to such products. AI4SWEng shall then contribute for reducing the burden of data scientists and developers by providing them a smart, interactive and auditable assistant which excel in data-related tasks.
Overview of the Data Preparation and Validation tool
The Data Preparation and Validation tool developed under AI4SWEng addresses the need for exploratory data analysis, which provides relevant metadata to a Reasoning Language Model (RLM). This RLM is responsible for establishing a preparation pipeline according to the downstream task description, executing it on the raw dataset and validating its outputs. A module called Automated Data Preparation Tool combines reasoning capabilities, Retrieval Augmented Generation and LLM tooling to establish a preparation pipeline and illustrate it using atomic preparation functions such as feature encoders, samplers or sanitisers. This approach has been chosen rather than the already existing python code generation for data preparation to prevent hallucinations and frame the preparation capabilities to a set of tools. Concerning the evaluation modules, they both assess the preparation quality independently by validating previously established criteria on the data or by running specific model unit tests to ensure that the targeted models can ingest the prepared data without any error.
The Data Preparation and Validation tool distinguishes itself by its state-machine architecture which allows the end-user to participate in the preparation process by integrating him in the loop. Another differentiating point is the generation of provenance files at each step of the preparation pipeline. Those files are stored in a Data Warehouse Agent alongside the corresponding prepared version of the dataset and shall enable transparency, auditability and reuse of existing preparation pipeline.
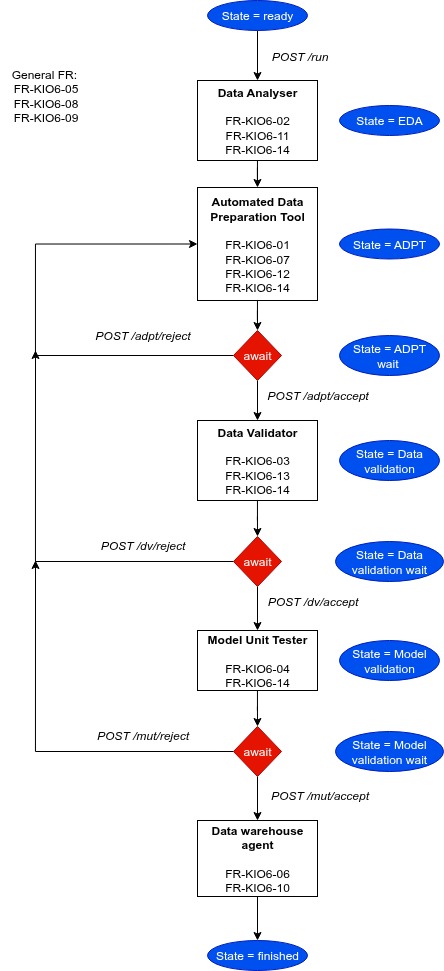
Architecture diagram of the Data Preparation and Validation microservice prototype
Overview of the Synthetic Data Generation tool
On the other hand, the Synthetic Data Generation tool addresses the need for domain-specific augmentation strategies which shall cover what generic algorithm such as Synthetic Minority Oversampling Technique (SMOTE) cannot. In the context of AI4SWEng, five diverse generation tasks are handled and present different constraints. Medical data generation requires an approach which handles multimodal data and protects data privacy whereas Geographical Information System data generation or Electric Vehicle Battery Lifecycle data need to handle complex data types such as rasters and time series data. Additionally, this module also enables data generation for training network intrusion detection systems and code vulnerability scanners. The synthetic datasets produced for each of these contexts are validated by dedicated evaluation framework which assess the data in terms of realism, diversity, downstream task performance and other specific metrics.
This module distinguishes itself by providing those diverse generation capabilities in the same wrapper, exposed as a microservice and an API. As for the previous tool, the microservice is designed as a state-machine which enables the end-user to interact with the generation process for accepting or rejecting the generation results. To enable transparency and auditability of the generated data, provenance files describing the generative models and associated hyperparameters, the seed datasets, and the generation metrics are produced and stored alongside the datasets and the weights of the AI models in the Data Warehouse Agent. At the end, this storing capability shall enable an efficient management of the generator versions for optimising the training process and reuse models where it’s relevant.
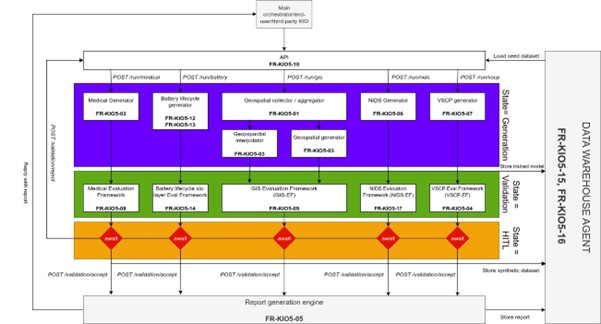
Architecture diagram of the Synthetic Data Generation microservice prototype
From standalone tools to a complete data engineering ecosystem
Although these modules can function independently, their greatest strength lies in their ability to work together as interoperable systems. The microservice architecture enables those tools to be called by the main orchestrator of the AI4SWEng Suite but also by other modules. Thus, the Synthetic Data Generation Tool can be considered by the Data Preparation and Validation tool as one of its preparation abilities and enable more complex and relevant data augmentation strategies. Altogether, the tools and capabilities developed in AI4SWEng accelerate the data curation process and free up time to the data scientist to focus on other high-value tasks.
